Engineering words for everyone
One interview question I enjoy getting as a mid-career engineer is, what’s the most impressive feat of engineering you’ve seen in your lifetime? I answer without doubt or hesitation. It’s UTF-8.
What do I find so impressive about UTF-8? Let’s go on a historical tour of the ways people convert words into signals for transmission and storage, character encodings.
 Diagram showing each letter and numeral with its Morse code representation.
Diagram showing each letter and numeral with its Morse code representation.
Morse code (1844). Initially assigned numbers to words using a codebook, like all of the other telegraph code systems. Instead started assigning codes to letters and having the letters spell out words on their own in 1840. Estimated letter frequency by looking at how many of each letter there were in typesetting equipment, assigning shorter codes to more common letters for faster transmission. Served as the US standard for over 100 years, emphasizing what a wildly powerful one-shot it was. International Morse, the version we use today, was standardized in 1865 based on German Morse. The OG. ★★★★☆
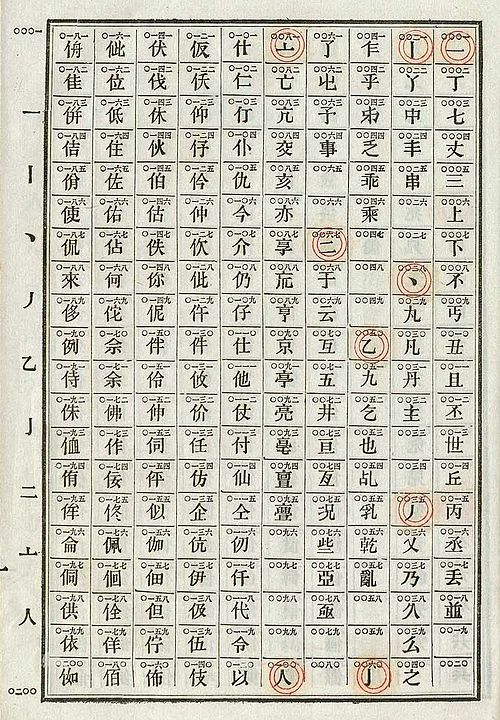 Photograph of an 1871 Chinese telegraph codebook, open to a table of 200 Chinese characters and their corresponding numeric codes.
Photograph of an 1871 Chinese telegraph codebook, open to a table of 200 Chinese characters and their corresponding numeric codes.
Chinese telegraph code (1871). An example of a ridiculously bad encoding. Designed by foreigners. Used the codebook approach to assign each Chinese character to a number from 0000 to 9999. Sent the number using International Morse. Numbers are the slowest characters to transmit in International Morse. Just about maximally slow. ★☆☆☆☆
 Screenshot of a Wikipedia page showing a table of EBCDIC glyphs and their corresponding hexadecimal codes.
Screenshot of a Wikipedia page showing a table of EBCDIC glyphs and their corresponding hexadecimal codes.
BCDIC (1928). Stands for Binary-Coded Decimal Interchange Code. A way to represent letters on punch cards designed for numbers by assigning a two-digit code to each letter. Developed by IBM for use in electromechanical tabulating machines. Represented 48 glyphs with the numbers 0-63. Extended into EBCDIC in 1964 (whence the E), used in IBM computers once those were invented. Perfectly serviceable. ★★★☆☆
 Table of the 128 ASCII characters and their corresponding decimal, hex, and binary representations.
Table of the 128 ASCII characters and their corresponding decimal, hex, and binary representations.
ASCII (1963). Stands for American Standard Code for Information Interchange. An elegant, logical mapping of every key a typewriter could produce, plus the most essential machine control instructions, into 128 glyphs. Really great for English text! The (American) IBM engineers definitely knew what they were doing by now. The only problem was that sometimes, some people wanted to display text that was not in English. Served as the US standard for 25 years. Brilliant and efficient. ★★★★☆
 Diagram showing the 256 glyphs represented in Latin-1.
Diagram showing the 256 glyphs represented in Latin-1.
Latin-1 (1985). Often called ANSI, which actually stands for American National Standards Institute. Actually developed by the European Computer Manufacturers Association, trying to construct a single text encoding that all of Europe could use. The limit of 256 glpyhs meant they had to make some tradeoffs, not fully supporting any language. Missing glyphs include French œ, German ẞ, Finnish š, and the Hungarian ő found in Erdős. Mostly solved the encoding problem for most European languages for the next 25 years. The rest of the world used a horrifying jumble of competing encodings (ask me about Shift-JIS some time.) A solid working solution for an intractable problem. ★★★☆☆
 Screenshot of xkcd comic 927. Transcription available at https://www.explainxkcd.com/wiki/index.php/927:_Standards
Screenshot of xkcd comic 927. Transcription available at https://www.explainxkcd.com/wiki/index.php/927:_Standards
Unicode (1991). Born of a utopian dream to develop one universal standard that covers everyone’s use cases. Aims to define a single encoding that can represent any text that any person has ever written. Governed by the Unicode Consortium. Ran into two seemingly insurmountable problems: 1. Using it doubled the size of text written in Latin-1. The fastest modems available in 1991 had a transfer rate of 1.2KiB/s, so it was critical to optimize even text transmission sizes. 2. It only had space for 65,536 glyphs. This is not enough glyphs to encode even all of modern Chinese. There was a proposal to expand the space to 4.2 billion glyphs, but at the unworkable cost of doubling the text size again. Points for originality, I guess. ★★☆☆☆
UTF-8 (1993). Stands for Unicode Transformation Format (8-bit). Radical solution that made everyone happy (except for CJK languages, which got screwed over by the consortium in the 1990s. Every country with its own script now has a seat on the consortium for this reason). Varies the length of the encoding based on the glyph, at the cost of significantly increased size and complexity. English could keep its precious 8-bit characters (128 glyphs), all European languages handily fit in 16 bits (2,048 glyphs), and even Classical Chinese has more than enough space at 32 bits (1.1 billion glyphs). The best character encoding so far. ★★★★★
 Screenshot of a graph showing the usage rates of character encodings on the Web each year from 2000 to 2012. UTF-8 goes from 0% to 64% while ASCII goes from 57% to 17%.
Screenshot of a graph showing the usage rates of character encodings on the Web each year from 2000 to 2012. UTF-8 goes from 0% to 64% while ASCII goes from 57% to 17%.
That earlier XKCD comic, which ran in 2011 when UTF-8 adoption was around 52%, specifically uses character encodings as an example of a universal standard that never actually works out. Today, 99% of all websites use UTF-8. Its wide rollout was not without its challenges, but by and large proceeded smoothly. Experienced programmers today wonder why they have to specify UTF-8 everywhere, when there’s hasn’t been a reason to consider anything else in the past 10 years. It’s like how every single DNS resource record since 1985 has had to specify “IN” so we know it’s on the Internet, and not some other global network it might have been on in the 1980s.
And that Internet in question? It runs on text. Text, which must have an encoding, makes up five of the seven layers that in turn make up the Internet. It’s like we took a plane in flight and swapped out all of its engines. And no one noticed. A monumental feat that no one outside the field is aware of. This is the kind of massive infrastructure upgrade that engineers everywhere should strive to emulate.